
Introduction
As I learnt from one of the Microsoft’s learning resource, machine learning answers mostly just five types of questions:
- Is this A or B (Classification Problem)
- How much? (Regression Problem)
- How is this organized? (Clustering Problem)
- Is this weird? (Anomaly Detection)
- What’s next? (Reinforcement learning)
We use use various algorithms and techniques to answer these questions. Machine learning is broadly classified in Supervised, Unsupervised, Deep-learning and Reinforcement learning.
Supervised learning: When we have labled data avaliable for applying machine learning techniques.
UnSupervised learning: When we do not have labled data avaliable for applying machine learning techniques.
Deep learning: This is a highly evolved branch of machine learning, where a model itself identifies the best features for the model with very less manual efforts and provide very high accuracies. Best to be used for image or sound data.
Reinforcement Learning: This area of machine learning is about taking suitable action to maximize reward in a particular situation, it i s employed by various software and machines to find the best possible behaviour or path it should take in a specific situation.
In this blog, I will dive deep in Naive Bayes Classifier, which is one of the most popular technique for classification problems in machine learning.
Naive Bayes Classifier
Naive bayes algorithim is derivied from the famous Baye’s theoram of probability.
Baye’s theoram of probability
Conditional Probability is basically trying to find a probability of an event based on a condition given or assumed. Notation for Conditional Probability is as follows:
P (A|B): This should be read as, probability of event A; given that event B already happened.
 provided P (B) >0
provided P (B) >0
Bayes’ theorem have subtle difference than Conditional Probability. In a nutshell, it gives you the actual probability of an event given information about tests.. Now its important to understand the terms Events and Tests, with respect to Probability.
- Events : “Events” Are different from “tests.” For example, there is a test for liver disease, but that’s separate from the event of actually having liver disease.
- Tests: Tests are flawed: just because you have a positive test does not mean you actually have the disease. Many tests have a high false positive rate. Rare events tend to have higher false positive rates than more common events. We’re not just talking about medical tests here. For example, spam filtering can have high false positive rates. Bayes’ theorem takes the test results and calculates your real probability that the test has identified the event.
Lets drive Baye’s Theoram:


This is the fourmala for Baye’s Theoram. Let’s understand what probability each part of the equation denotes.

Posterior Probability: Posterior probability is the probability an event will happen after all evidence or background information has been taken into account.
Likelihood: Probability is about a finite set of possible outcomes, given a probability. Likelihood is about an infinite set of possible probabilities, given an outcome.
Prior Probability: Prior probability, in Bayesian statistical inference, is the probability of an event before new data is collected. This is the best rational assessment of the probability of an outcome based on the current knowledge before an experiment is performed.
Marginal Probability: Marginal probability is the probability of an event irrespective of the outcome of another variable.
Naive Baye’s Classifier
As name suggests Naive Baye’s Classifier is used for Classification Problems, example : For a given problem statement answer is either TRUE or FLASE, whichever outcome will have higher probability will be our final outcome or final decision.
Let’s understand with the help of example,

Problem Statement: Is it a good day to play golf?
What we have in hand? Past data, that tells on whar kind of whether conditions golf was played.
In table above (which is our dataset) columns Outlook, temperature, Humidity, Windy are the features for the dataset and will be representated as dataset X and it have features {x1,x2,x3……..xn} and column Play Golf is the outcome and will represented as Class variable {y} with possible outcomes Yes/No.
The datset can be read as : A Rainy, Hot and highly humid day is not good to play Golf and also a Sunny, Cool, Normal Humid and non windy day is good to play golf.
Based on our dataset the Baye’s Theoram can be re-written as :

Now as we know, X have features {x1,x2,x3……..xn}, we can replace the dataset X with features as below:

As the denominator remains constant the above equation can be rewritten as:

Now as I mentioned in my first statement in Naive Baye’s which ever class will have highest probability will be the outcome, so we can simply fetch maximum probability using argmax function on y:

And this is how a Classification problem is solved using Naive Baye’s Classifier.







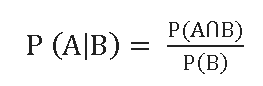 provided P (B) >0
provided P (B) >0




